Introduction
LunchBoxML implements Microsoft’s ML.NET to provide Grasshopper users with the ability to train, save, and test Machine Learning models using a variety of algorithms including regression, binary classification, and multiclass classification.
To utilize the ML.NET components, this page describes a general workflow pattern that should be implemented:
Data Preparation
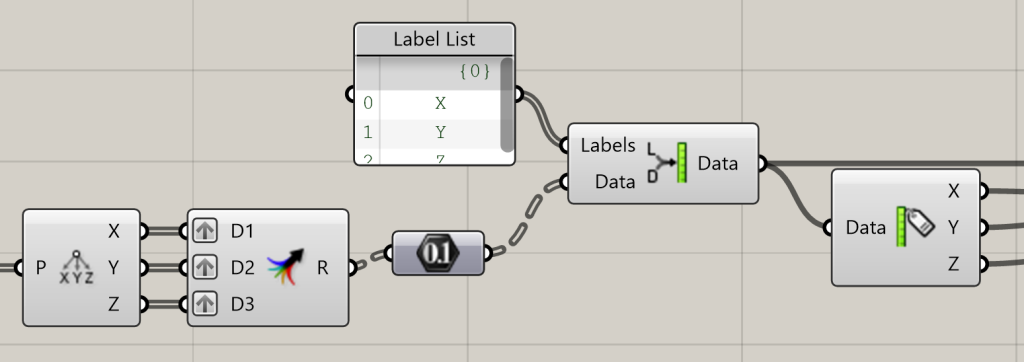
LunchBoxML includes a useful set of ‘Data Set’ components that can be used to prepare Grasshopper data for use in training and testing models. Data sets can be created within the Grasshopper definition or read in from an external text files.
You can think of data sets as a way to organize and structure your data into a table with labeled fields. The labels and associated data are essential for using supervised learning algorithms such as regression and binary classification methods.
Model Creation
After defining your data set, you can then determine what training model to use that will suit your data use:
- Regression trainers are useful for analyzing relationships between numeric input labels and their output – think defining predictive ‘fit curves’ or other forms of numeric forecasting.
- Binary classification trainers are useful in determining true/false or yes/no classification outputs given a set of inputs.
- Multiclass Classification trainers are useful in determining a variety of classifications given a set of inputs – like determining if a set of inputs should receive a particular name or identifier.
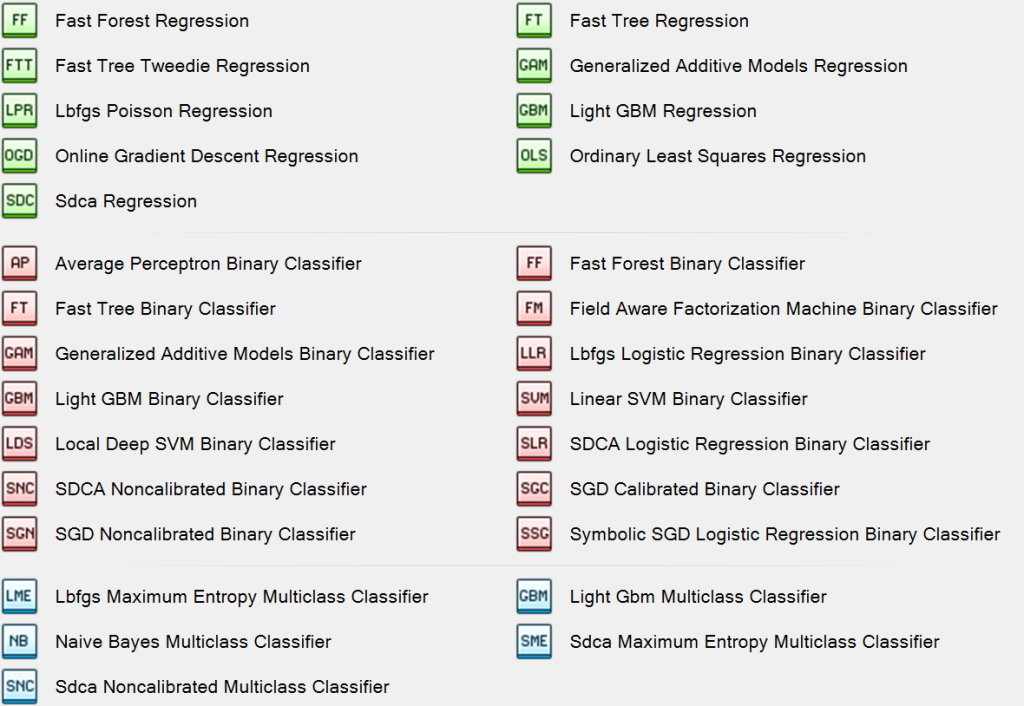
Trainer Type Selection
Trainer types refer to the specific algorithm that should be implemented by the Model trainer. The selection of your trainer type will depend greatly on the nuances of your specific model and the goal for your prediction.
Experiment with different trainer types for regression, binary classification, and multiclass classification to discover what best suits your use case.
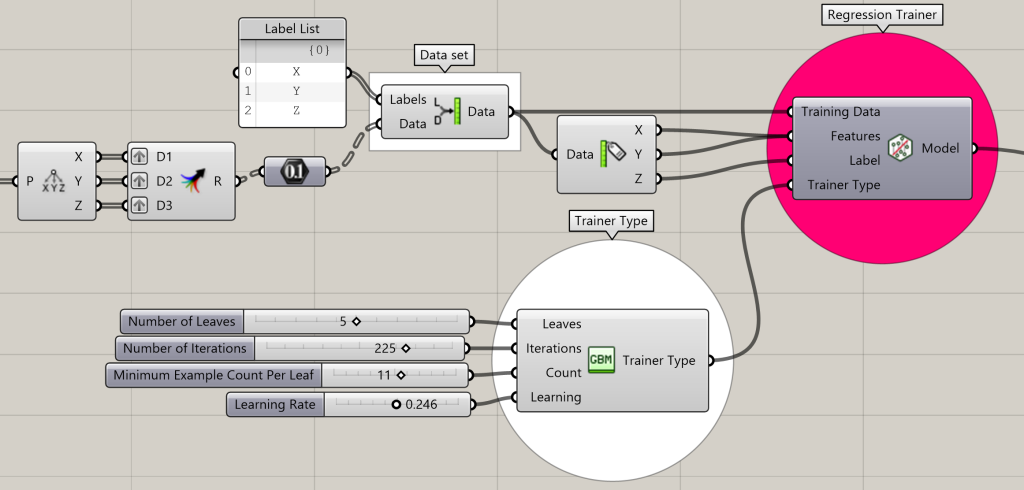
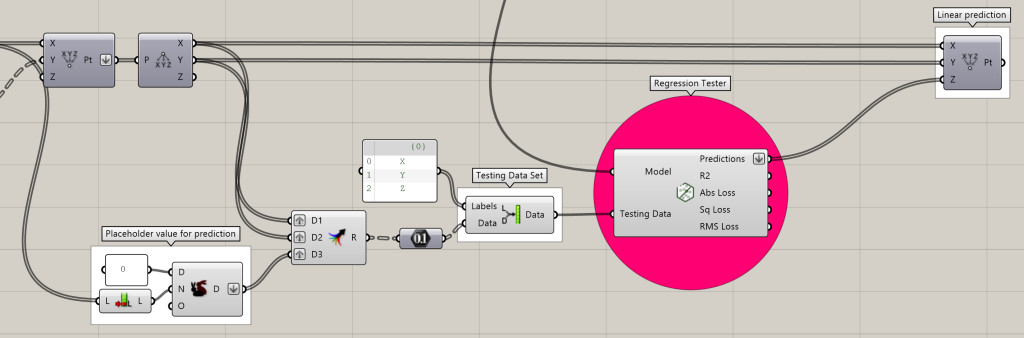
Model Testing
After you have trained your Model, you can then ‘test’ the model against new data. The predictive effectiveness of the model will depend greatly on both the quantity and quality of your model’s training data as well as the selection of an appropriate trainer type.
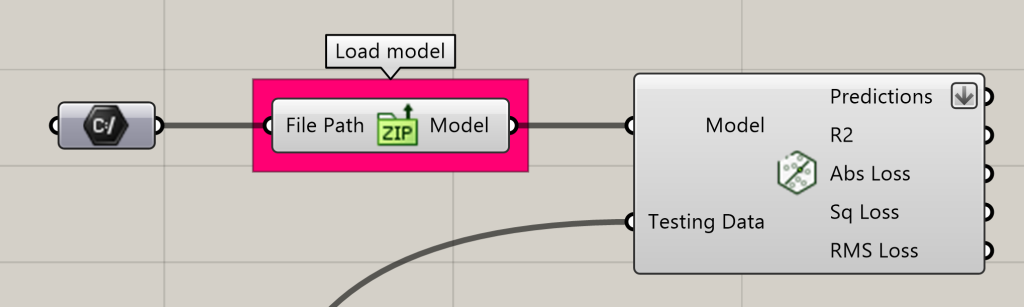
Saving and Loading models
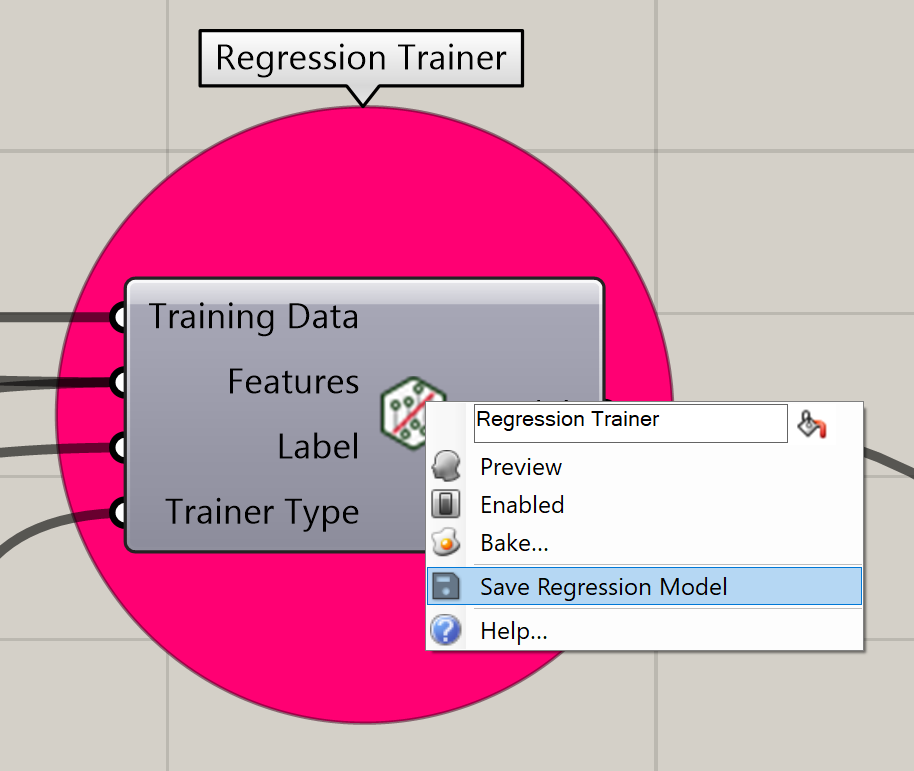
After you have trained a model, that model can be reused in your Grasshopper definitions as a pre-trained model. This means that your definitions need not re-train your models upon each execution (which can be computationally expensive!)
By right-clicking on your Model trainer, you will see an option to Save the trainer to a Zip file.